
The first seven episodes of the season are streaming now on Max.The first seven episodes of the season are streaming…
Browsing: Tech
tech news
The Space Force said Thursday its newest weather satellite is now operational and will soon be collecting and sharing key…
Thousands of NVIDIA Grace Blackwell GPUs Now Live at CoreWeave, Propelling Development for AI Pioneerson April 15, 2025 at 6:00 pm
Post Content
CoreWeave today became one of the first cloud providers to bring NVIDIA GB200 NVL72 systems online for customers at scale, and AI frontier companies Cohere, IBM and Mistral AI are already using them to train and deploy next-generation AI models and applications.
CoreWeave, the first cloud provider to make NVIDIA Grace Blackwell generally available, has already shown incredible results in MLPerf benchmarks with NVIDIA GB200 NVL72 — a powerful rack-scale accelerated computing platform designed for reasoning and AI agents. Now, CoreWeave customers are gaining access to thousands of NVIDIA Blackwell GPUs.
“We work closely with NVIDIA to quickly deliver to customers the latest and most powerful solutions for training AI models and serving inference,” said Mike Intrator, CEO of CoreWeave. “With new Grace Blackwell rack-scale systems in hand, many of our customers will be the first to see the benefits and performance of AI innovators operating at scale.”

The ramp-up for customers of cloud providers like CoreWeave is underway. Systems built on NVIDIA Grace Blackwell are in full production, transforming cloud data centers into AI factories that manufacture intelligence at scale and convert raw data into real-time insights with speed, accuracy and efficiency.
Leading AI companies around the world are now putting GB200 NVL72’s capabilities to work for AI applications, agentic AI and cutting-edge model development.
Personalized AI Agents
Cohere is using its Grace Blackwell Superchips to help develop secure enterprise AI applications powered by leading-edge research and model development techniques. Its enterprise AI platform, North, enables teams to build personalized AI agents to securely automate enterprise workflows, surface real-time insights and more.
With NVIDIA GB200 NVL72 on CoreWeave, Cohere is already experiencing up to 3x more performance in training for 100 billion-parameter models compared with previous-generation NVIDIA Hopper GPUs — even without Blackwell-specific optimizations.
With further optimizations taking advantage of GB200 NVL72’s large unified memory, FP4 precision and a 72-GPU NVIDIA NVLink domain — where every GPU is connected to operate in concert — Cohere is getting dramatically higher throughput with shorter time to first and subsequent tokens for more performant, cost-effective inference.
“With access to some of the first NVIDIA GB200 NVL72 systems in the cloud, we are pleased with how easily our workloads port to the NVIDIA Grace Blackwell architecture,” said Autumn Moulder, vice president of engineering at Cohere. “This unlocks incredible performance efficiency across our stack — from our vertically integrated North application running on a single Blackwell GPU to scaling training jobs across thousands of them. We’re looking forward to achieving even greater performance with additional optimizations soon.”
AI Models for Enterprise
IBM is using one of the first deployments of NVIDIA GB200 NVL72 systems, scaling to thousands of Blackwell GPUs on CoreWeave, to train its next-generation Granite models, a series of open-source, enterprise-ready AI models. Granite models deliver state-of-the-art performance while maximizing safety, speed and cost efficiency. The Granite model family is supported by a robust partner ecosystem that includes leading software companies embedding large language models into their technologies.
Granite models provide the foundation for solutions like IBM watsonx Orchestrate, which enables enterprises to build and deploy powerful AI agents that automate and accelerate workflows across the enterprise.
CoreWeave’s NVIDIA GB200 NVL72 deployment for IBM also harnesses the IBM Storage Scale System, which delivers exceptional high-performance storage for AI. CoreWeave customers can access the IBM Storage platform within CoreWeave’s dedicated environments and AI cloud platform.
“We are excited to see the acceleration that NVIDIA GB200 NVL72 can bring to training our Granite family of models,” said Sriram Raghavan, vice president of AI at IBM Research. “This collaboration with CoreWeave will augment IBM’s capabilities to help build advanced, high-performance and cost-efficient models for powering enterprise and agentic AI applications with IBM watsonx.”
Compute Resources at Scale
Mistral AI is now getting its first thousand Blackwell GPUs to build the next generation of open-source AI models.
Mistral AI, a Paris-based leader in open-source AI, is using CoreWeave’s infrastructure, now equipped with GB200 NVL72, to speed up the development of its language models. With models like Mistral Large delivering strong reasoning capabilities, Mistral needs fast computing resources at scale.
To train and deploy these models effectively, Mistral AI requires a cloud provider that offers large, high-performance GPU clusters with NVIDIA Quantum InfiniBand networking and reliable infrastructure management. CoreWeave’s experience standing up NVIDIA GPUs at scale with industry-leading reliability and resiliency through tools such as CoreWeave Mission Control met these requirements.
“Right out of the box and without any further optimizations, we saw a 2x improvement in performance for dense model training,” said Thimothee Lacroix, cofounder and chief technology officer at Mistral AI. “What’s exciting about NVIDIA GB200 NVL72 is the new possibilities it opens up for model development and inference.”
A Growing Number of Blackwell Instances
In addition to long-term customer solutions, CoreWeave offers instances with rack-scale NVIDIA NVLink across 72 NVIDIA Blackwell GPUs and 36 NVIDIA Grace CPUs, scaling to up to 110,000 GPUs with NVIDIA Quantum-2 InfiniBand networking.
These instances, accelerated by the NVIDIA GB200 NVL72 rack-scale accelerated computing platform, provide the scale and performance needed to build and deploy the next generation of AI reasoning models and agents.
Thousands of NVIDIA Grace Blackwell GPUs Now Live at CoreWeave, Propelling Development for AI Pioneerson April 15, 2025 at 6:00 pm
Post Content
CoreWeave today became one of the first cloud providers to bring NVIDIA GB200 NVL72 systems online for customers at scale, and AI frontier companies Cohere, IBM and Mistral AI are already using them to train and deploy next-generation AI models and applications.
CoreWeave, the first cloud provider to make NVIDIA Grace Blackwell generally available, has already shown incredible results in MLPerf benchmarks with NVIDIA GB200 NVL72 — a powerful rack-scale accelerated computing platform designed for reasoning and AI agents. Now, CoreWeave customers are gaining access to thousands of NVIDIA Blackwell GPUs.
“We work closely with NVIDIA to quickly deliver to customers the latest and most powerful solutions for training AI models and serving inference,” said Mike Intrator, CEO of CoreWeave. “With new Grace Blackwell rack-scale systems in hand, many of our customers will be the first to see the benefits and performance of AI innovators operating at scale.”
The ramp-up for customers of cloud providers like CoreWeave is underway. Systems built on NVIDIA Grace Blackwell are in full production, transforming cloud data centers into AI factories that manufacture intelligence at scale and convert raw data into real-time insights with speed, accuracy and efficiency.
Leading AI companies around the world are now putting GB200 NVL72’s capabilities to work for AI applications, agentic AI and cutting-edge model development.
Personalized AI Agents
Cohere is using its Grace Blackwell Superchips to help develop secure enterprise AI applications powered by leading-edge research and model development techniques. Its enterprise AI platform, North, enables teams to build personalized AI agents to securely automate enterprise workflows, surface real-time insights and more.
With NVIDIA GB200 NVL72 on CoreWeave, Cohere is already experiencing up to 3x more performance in training for 100 billion-parameter models compared with previous-generation NVIDIA Hopper GPUs — even without Blackwell-specific optimizations.
With further optimizations taking advantage of GB200 NVL72’s large unified memory, FP4 precision and a 72-GPU NVIDIA NVLink domain — where every GPU is connected to operate in concert — Cohere is getting dramatically higher throughput with shorter time to first and subsequent tokens for more performant, cost-effective inference.
“With access to some of the first NVIDIA GB200 NVL72 systems in the cloud, we are pleased with how easily our workloads port to the NVIDIA Grace Blackwell architecture,” said Autumn Moulder, vice president of engineering at Cohere. “This unlocks incredible performance efficiency across our stack — from our vertically integrated North application running on a single Blackwell GPU to scaling training jobs across thousands of them. We’re looking forward to achieving even greater performance with additional optimizations soon.”
AI Models for Enterprise
IBM is using one of the first deployments of NVIDIA GB200 NVL72 systems, scaling to thousands of Blackwell GPUs on CoreWeave, to train its next-generation Granite models, a series of open-source, enterprise-ready AI models. Granite models deliver state-of-the-art performance while maximizing safety, speed and cost efficiency. The Granite model family is supported by a robust partner ecosystem that includes leading software companies embedding large language models into their technologies.
Granite models provide the foundation for solutions like IBM watsonx Orchestrate, which enables enterprises to build and deploy powerful AI agents that automate and accelerate workflows across the enterprise.
CoreWeave’s NVIDIA GB200 NVL72 deployment for IBM also harnesses the IBM Storage Scale System, which delivers exceptional high-performance storage for AI. CoreWeave customers can access the IBM Storage platform within CoreWeave’s dedicated environments and AI cloud platform.
“We are excited to see the acceleration that NVIDIA GB200 NVL72 can bring to training our Granite family of models,” said Sriram Raghavan, vice president of AI at IBM Research. “This collaboration with CoreWeave will augment IBM’s capabilities to help build advanced, high-performance and cost-efficient models for powering enterprise and agentic AI applications with IBM watsonx.”
Compute Resources at Scale
Mistral AI is now getting its first thousand Blackwell GPUs to build the next generation of open-source AI models.
Mistral AI, a Paris-based leader in open-source AI, is using CoreWeave’s infrastructure, now equipped with GB200 NVL72, to speed up the development of its language models. With models like Mistral Large delivering strong reasoning capabilities, Mistral needs fast computing resources at scale.
To train and deploy these models effectively, Mistral AI requires a cloud provider that offers large, high-performance GPU clusters with NVIDIA Quantum InfiniBand networking and reliable infrastructure management. CoreWeave’s experience standing up NVIDIA GPUs at scale with industry-leading reliability and resiliency through tools such as CoreWeave Mission Control met these requirements.
“Right out of the box and without any further optimizations, we saw a 2x improvement in performance for dense model training,” said Thimothee Lacroix, cofounder and chief technology officer at Mistral AI. “What’s exciting about NVIDIA GB200 NVL72 is the new possibilities it opens up for model development and inference.”
A Growing Number of Blackwell Instances
In addition to long-term customer solutions, CoreWeave offers instances with rack-scale NVIDIA NVLink across 72 NVIDIA Blackwell GPUs and 36 NVIDIA Grace CPUs, scaling to up to 110,000 GPUs with NVIDIA Quantum-2 InfiniBand networking.
These instances, accelerated by the NVIDIA GB200 NVL72 rack-scale accelerated computing platform, provide the scale and performance needed to build and deploy the next generation of AI reasoning models and agents.
The Space Force said Thursday its newest weather satellite is now operational and will soon be collecting and sharing key…
Global bank Citi has predicted 2025 could be a possible inflection point for blockchain adoption driven by stablecoins, akin to…
Don’t know what to watch? Dig through these Netflix movie picks in animation, drama and more.Don’t know what to watch?…
The Space Force said Thursday its newest weather satellite is now operational and will soon be collecting and sharing key…
The Space Force said Thursday its newest weather satellite is now operational and will soon be collecting and sharing key…
Keeping AI on the Planet: NVIDIA Technologies Make Every Day About Earth Dayon April 22, 2025 at 1:00 pm
Whether at sea, land or in the sky — even outer space — NVIDIA technology is helping research scientists and developers alike explore and understand oceans, wildlife, the climate and far out existential risks like asteroids. These increasingly intelligent developments are helping to analyze environmental pollutants, damage to habitats and natural disaster risks at an
Read ArticleWhether at sea, land or in the sky — even outer space — NVIDIA technology is helping research scientists and developers alike explore and understand oceans, wildlife, the climate and far out existential risks like asteroids. These increasingly intelligent developments are helping to analyze environmental pollutants, damage to habitats and natural disaster risks at an
Read Article
Whether at sea, land or in the sky — even outer space — NVIDIA technology is helping research scientists and developers alike explore and understand oceans, wildlife, the climate and far out existential risks like asteroids.
These increasingly intelligent developments are helping to analyze environmental pollutants, damage to habitats and natural disaster risks at an accelerated pace. This, in turn, enables partnerships with local governments to take climate mitigation steps like pollution prevention and proactive planting.
Sailing the Seas of AI
Amphitrite, based in France, uses satellite data with AI to simulate and predict ocean currents and weather. Its AI models, driven by the NVIDIA AI and Earth-2 platforms, offer insights for positioning vessels to best harness the power of ocean currents. This helps determine when it’s best to travel, as well as the optimal course, reducing travel times, fuel consumption and carbon emissions. Amphitrite is a member of the NVIDIA Inception program for cutting-edge startups.
Watching Over Wildlife With AI
München, Germany-based OroraTech monitors animal poaching and wildfires with NVIDIA CUDA and Jetson. The NVIDIA Inception program member uses the EarthRanger platform to offer a wildfire detection and monitoring service that uses satellite imagery and AI to safeguard the environment and prevent poaching.
Keeping AI on the Weather
Weather agencies and climate scientists worldwide are using NVIDIA CorrDiff, a generative AI weather model enabling kilometer-scale forecasts of wind, temperature and precipitation type and amount. CorrDiff is part of the NVIDIA Earth-2 platform for simulating weather and climate conditions. It’s available as an easy-to-deploy NVIDIA NIM microservice.
In another climate effort, NVIDIA Research announced a new generative AI model, called StormCast, for reliable weather prediction at a scale larger than storms.
The model, outlined in a paper, can help with disaster and mitigation planning, saving lives.
Avoiding Mass Extinction Events
Researchers reported in Nature how a new method was able to spot 10-meter asteroids within the main asteroid belt located between Jupiter and Mars. Such space rocks can range from bus-sized to several Costco stores in width and deliver destruction to cities. It used NASA’s James Webb Space Telescope (JWST), which was tapped for views of these asteroids from previous research and enabled by NVIDIA accelerated computing.

Boosting Energy Efficiency With Liquid-Cooled Blackwell
NVIDIA GB200 NVL72 rack-scale, liquid-cooled systems, built on the Blackwell platform, offer exceptional performance while balancing energy costs and heat. It delivers 40x higher revenue potential, 30x higher throughput, 25x more energy efficiency and 300x more water efficiency than air-cooled architectures. NVIDIA GB300 NVL72 systems built on the Blackwell Ultra platform offer a 50x higher revenue potential, 35x higher throughput with 30x more energy efficiency.
Enroll in the free new NVIDIA Deep Learning Institute course Applying AI Weather Models With NVIDIA Earth-2. Learn more about NVIDIA Earth-2 and NVIDIA Blackwell.
Whether at sea, land or in the sky — even outer space — NVIDIA technology is helping research scientists and developers alike explore and understand oceans, wildlife, the climate and far out existential risks like asteroids. These increasingly intelligent developments are helping to analyze environmental pollutants, damage to habitats and natural disaster risks at an
Read Article
Chill Factor: NVIDIA Blackwell Platform Boosts Water Efficiency by Over 300xon April 22, 2025 at 1:00 pm
Traditionally, data centers have relied on air cooling — where mechanical chillers circulate chilled air to absorb heat from servers, helping them maintain optimal conditions. But as AI models increase in size, and the use of AI reasoning models rises, maintaining those optimal conditions is not only getting harder and more expensive — but more
Read ArticleTraditionally, data centers have relied on air cooling — where mechanical chillers circulate chilled air to absorb heat from servers, helping them maintain optimal conditions. But as AI models increase in size, and the use of AI reasoning models rises, maintaining those optimal conditions is not only getting harder and more expensive — but more
Read Article
Traditionally, data centers have relied on air cooling — where mechanical chillers circulate chilled air to absorb heat from servers, helping them maintain optimal conditions. But as AI models increase in size, and the use of AI reasoning models rises, maintaining those optimal conditions is not only getting harder and more expensive — but more energy-intensive.
While data centers once operated at 20 kW per rack, today’s hyperscale facilities can support over 135 kW per rack, making it an order of magnitude harder to dissipate the heat generated by high-density racks. To keep AI servers running at peak performance, a new approach is needed for efficiency and scalability.
One key solution is liquid cooling — by reducing dependence on chillers and enabling more efficient heat rejection, liquid cooling is driving the next generation of high-performance, energy-efficient AI infrastructure.
The NVIDIA GB200 NVL72 and the NVIDIA GB300 NVL72 are rack-scale, liquid-cooled systems designed to handle the demanding tasks of trillion-parameter large language model inference. Their architecture is also specifically optimized for test-time scaling accuracy and performance, making it an ideal choice for running AI reasoning models while efficiently managing energy costs and heat.

Driving Unprecedented Water Efficiency and Cost Savings in AI Data Centers
Historically, cooling alone has accounted for up to 40% of a data center’s electricity consumption, making it one of the most significant areas where efficiency improvements can drive down both operational expenses and energy demands.
Liquid cooling helps mitigate costs and energy use by capturing heat directly at the source. Instead of relying on air as an intermediary, direct-to-chip liquid cooling transfers heat in a technology cooling system loop. That heat is then cycled through a coolant distribution unit via liquid-to-liquid heat exchanger, and ultimately transferred to a facility cooling loop. Because of the higher efficiency of this heat transfer, data centers and AI factories can operate effectively with warmer water temperatures — reducing or eliminating the need for mechanical chillers in a wide range of climates.
The NVIDIA GB200 NVL72 rack-scale, liquid-cooled system, built on the NVIDIA Blackwell platform, offers exceptional performance while balancing energy costs and heat. It packs unprecedented compute density into each server rack, delivering 40x higher revenue potential, 30x higher throughput, 25x more energy efficiency and 300x more water efficiency than traditional air-cooled architectures. Newer NVIDIA GB300 NVL72 systems built on the Blackwell Ultra platform boast a 50x higher revenue potential and 35x higher throughput with 30x more energy efficiency.
Data centers spend an estimated $1.9-2.8M per megawatt (MW) per year, which amounts to nearly $500,000 spent annually on cooling-related energy and water costs. By deploying the liquid-cooled GB200 NVL72 system, hyperscale data centers and AI factories can achieve up to 25x cost savings, leading to over $4 million dollars in annual savings for a 50 MW hyperscale data center.
For data center and AI factory operators, this means lower operational costs, enhanced energy efficiency metrics and a future-proof infrastructure that scales AI workloads efficiently — without the unsustainable water footprint of legacy cooling methods.
Moving Heat Outside the Data Center
As compute density rises and AI workloads drive unprecedented thermal loads, data centers and AI factories must rethink how they remove heat from their infrastructure. The traditional methods of heat rejection that supported predictable CPU-based scaling are no longer sufficient on their own. Today, there are multiple options for moving heat outside the facility, but four major categories dominate current and emerging deployments.
Key Cooling Methods in a Changing Landscape
- Mechanical Chillers: Mechanical chillers use a vapor compression cycle to cool water, which is then circulated through the data center to absorb heat. These systems are typically air-cooled or water-cooled, with the latter often paired with cooling towers to reject heat. While chillers are reliable and effective across diverse climates, they are also highly energy-intensive. In AI-scale facilities where power consumption and sustainability are top priorities, reliance on chillers can significantly impact both operational costs and carbon footprint.
- Evaporative Cooling: Evaporative cooling uses the evaporation of water to absorb and remove heat. This can be achieved through direct or indirect systems, or hybrid designs. These systems are much more energy-efficient than chillers but come with high water consumption. In large facilities, they can consume millions of gallons of water per megawatt annually. Their performance is also climate-dependent, making them less effective in humid or water-restricted regions.
- Dry Coolers: Dry coolers remove heat by transferring it from a closed liquid loop to the ambient air using large finned coils, much like an automotive radiator. These systems don’t rely on water and are ideal for facilities aiming to reduce water usage or operate in dry climates. However, their effectiveness depends heavily on the temperature of the surrounding air. In warmer environments, they may struggle to keep up with high-density cooling demands unless paired with liquid-cooled IT systems that can tolerate higher operating temperatures.
- Pumped Refrigerant Systems: Pumped refrigerant systems use liquid refrigerants to move heat from the data center to outdoor heat exchangers. Unlike chillers, these systems don’t rely on large compressors inside the facility and they operate without the use of water. This method offers a thermodynamically efficient, compact and scalable solution that works especially well for edge deployments and water-constrained environments. Proper refrigerant handling and monitoring are required, but the benefits in power and water savings are significant.
Each of these methods offers different advantages depending on factors like climate, rack density, facility design and sustainability goals. As liquid cooling becomes more common and servers are designed to operate with warmer water, the door opens to more efficient and environmentally friendly cooling strategies — reducing both energy and water use while enabling higher compute performance.
Optimizing Data Centers for AI Infrastructure
As AI workloads grow exponentially, operators are reimagining data center design with infrastructure built specifically for high-performance AI and energy efficiency. Whether they’re transforming their entire setup into dedicated AI factories or upgrading modular components, optimizing inference performance is crucial for managing costs and operational efficiency.
To get the best performance, high compute capacity GPUs aren’t enough — they need to be able to communicate with each other at lightning speed.
NVIDIA NVLink boosts communication, enabling GPUs to operate as a massive, tightly integrated processing unit for maximum performance with a full-rack power density of 120 kW. This tight, high-speed communication is crucial for today’s AI tasks, where every second saved on transferring data can mean more tokens per second and more efficient AI models.
Traditional air cooling struggles at these power levels. To keep up, data center air would need to be either cooled to below-freezing temperatures or flow at near-gale speeds to carry the heat away, making it increasingly impractical to cool dense racks with air alone.
At nearly 1,000x the density of air, liquid cooling excels at carrying heat away thanks to its superior heat capacitance and thermal conductivity. By efficiently transferring heat away from high-performance GPUs, liquid cooling reduces reliance on energy-intensive and noisy cooling fans, allowing more power to be allocated to computation rather than cooling overhead.
Liquid Cooling in Action
Innovators across the industry are leveraging liquid cooling to slash energy costs, improve density and drive AI efficiency:
- Vertiv’s reference architecture for NVIDIA GB200 NVL72 servers reduces annual energy consumption by 25%, cuts rack space requirements by 75% and shrinks the power footprint by 30%.
- Schneider Electric’s liquid-cooling infrastructure supports up to 132 kW per rack, improving energy efficiency, scalability and overall performance for GB200 NVL72 AI data centers.
- CoolIT Systems’ high-density CHx2000 liquid-to-liquid coolant distribution units provide 2MW cooling capacity at 5°C approach temperature, ensuring reliable thermal management for GB300 NVL72 deployments. Also, CoolIT Systems’ OMNI All-Metal Coldplates with patented Split-Flow technology provide targeted cooling of over 4,000W thermal design power while reducing pressure drop.
- Boyd’s advanced liquid-cooling solutions, incorporating the company’s over two decades of high-performance compute industry experience, include coolant distribution units, liquid-cooling loops and cold plates to further maximize energy efficiency and system reliability for high-density AI workloads.
Cloud service providers are also adopting cutting-edge cooling and power innovations. Next-generation AWS data centers, featuring jointly developed liquid cooling solutions, increase compute power by 12% while reducing energy consumption by up to 46% — all while maintaining water efficiency.
Cooling the AI Infrastructure of the Future
As AI continues to push the limits of computational scale, innovations in cooling will be essential to meeting the thermal management challenges of the post-Moore’s law era.
NVIDIA is leading this transformation through initiatives like the COOLERCHIPS program, a U.S. Department of Energy-backed effort to develop modular data centers with next-generation cooling systems that are projected to reduce costs by at least 5% and improve efficiency by 20% over traditional air-cooled designs.
Looking ahead, data centers must evolve not only to support AI’s growing demands but do so sustainably — maximizing energy and water efficiency while minimizing environmental impact. By embracing high-density architectures and advanced liquid cooling, the industry is paving the way for a more efficient AI-powered future.
Learn more about breakthrough solutions for data center energy and water efficiency presented at NVIDIA GTC 2025 and discover how accelerated computing is driving a more efficient future with NVIDIA Blackwell.
Traditionally, data centers have relied on air cooling — where mechanical chillers circulate chilled air to absorb heat from servers, helping them maintain optimal conditions. But as AI models increase in size, and the use of AI reasoning models rises, maintaining those optimal conditions is not only getting harder and more expensive — but more
Read Article
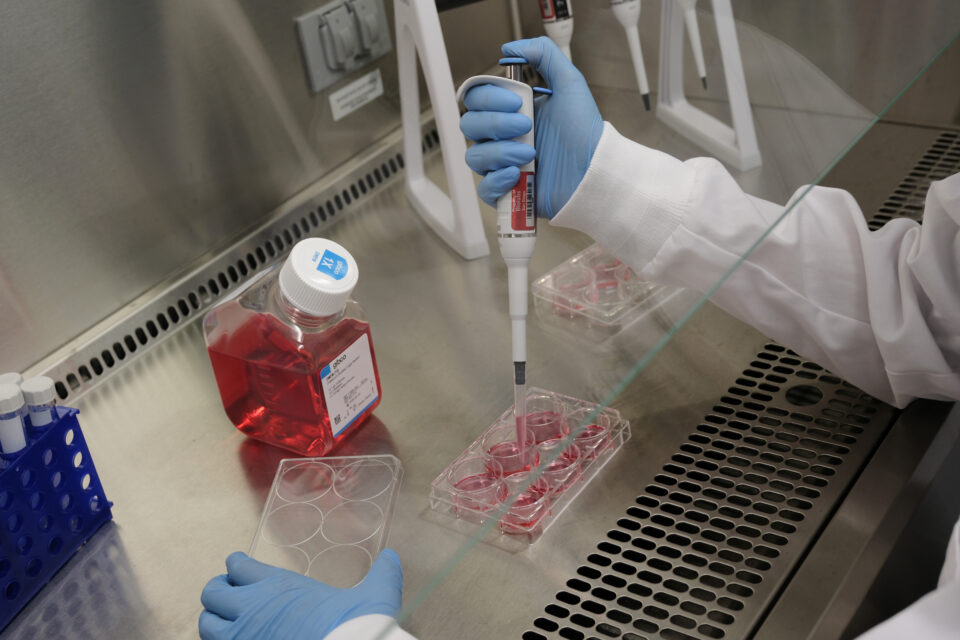
Making Brain Waves: AI Startup Speeds Disease Research With Lab in the Loopon April 22, 2025 at 1:00 pm
About 15% of the world’s population — over a billion people — are affected by neurological disorders, from commonly known diseases like Alzheimer’s and Parkinson’s to hundreds of lesser-known, rare conditions. BrainStorm Therapeutics, a San Diego-based startup, is accelerating the development of cures for these conditions using AI-powered computational drug discovery paired with lab experiments
Read ArticleAbout 15% of the world’s population — over a billion people — are affected by neurological disorders, from commonly known diseases like Alzheimer’s and Parkinson’s to hundreds of lesser-known, rare conditions. BrainStorm Therapeutics, a San Diego-based startup, is accelerating the development of cures for these conditions using AI-powered computational drug discovery paired with lab experiments
Read Article
About 15% of the world’s population — over a billion people — are affected by neurological disorders, from commonly known diseases like Alzheimer’s and Parkinson’s to hundreds of lesser-known, rare conditions.
BrainStorm Therapeutics, a San Diego-based startup, is accelerating the development of cures for these conditions using AI-powered computational drug discovery paired with lab experiments using organoids: tiny, 3D bundles of brain cells created from patient-derived stem cells. This hybrid, iterative method, where clinical data and AI models inform one another to accelerate drug development, is known as lab in the loop.
“The brain is the last frontier in modern biology,” said BrainStorm’s founder and CEO Robert Fremeau, who was previously a scientific director in neuroscience at Amgen and a faculty member at Duke University and the University of California, San Francisco. “By combining our organoid disease models with the power of generative AI, we now have the ability to start to unravel the underlying complex biology of disease networks.”
The company aims to lower the failure rate of drug candidates for brain diseases during clinical trials — currently over 93% — and identify therapeutics that can be applied to multiple diseases. Achieving these goals would make it faster and more economically viable to develop treatments for rare and common conditions.
“This alarmingly high clinical trial failure rate is mainly due to the inability of traditional preclinical models with rodents or 2D cells to predict human efficacy,” said Jun Yin, cofounder and chief technology officer at BrainStorm. “By integrating human-derived brain organoids with AI-driven analysis, we’re building a platform that better reflects the complexity of human neurobiology and improves the likelihood of clinical success.”
Fremeau and Yin believe that BrainStorm’s platform has the potential to accelerate development timelines, reduce research and development costs, and significantly increase the probability of bringing effective therapies to patients.
BrainStorm Therapeutics’ AI models, which run on NVIDIA GPUs in the cloud, were developed using the NVIDIA BioNeMo Framework, a set of programming tools, libraries and models for computational drug discovery. The company is a member of NVIDIA Inception, a global network of cutting-edge startups.
Clinical Trial in a Dish
BrainStorm Therapeutics uses AI models to develop gene maps of brain diseases, which they can use to identify promising targets for potential drugs and clinical biomarkers. Organoids allow them to screen thousands of drug molecules per day directly on human brain cells, enabling them to test the effectiveness of potential therapies before starting clinical trials.
“Brains have brain waves that can be picked up in a scan like an EEG, or electroencephalogram, which measures the electrical activity of neurons,” said Maya Gosztyla, the company’s cofounder and chief operating officer. “Our organoids also have spontaneous brain waves, allowing us to model the complex activity that you would see in the human brain in this much smaller system. We treat it like a clinical trial in a dish for studying brain diseases.”
BrainStorm Therapeutics is currently using patient-derived organoids for its work on drug discovery for Parkinson’s disease, a condition tied to the loss of neurons that produce dopamine, a neurotransmitter that helps with physical movement and cognition.
“In Parkinson’s disease, multiple genetic variants contribute to dysfunction across different cellular pathways, but they converge on a common outcome — the loss of dopamine neurons,” Fremeau said. “By using AI models to map and analyze the biological effects of these variants, we can discover disease-modifying treatments that have the potential to slow, halt or even reverse the progression of Parkinson’s.”
The BrainStorm team used single-cell sequencing data from brain organoids to fine-tune foundation models available through the BioNeMo Framework, including the Geneformer model for gene expression analysis. The organoids were derived from patients with mutations in the GBA1 gene, the most common genetic risk factor for Parkinson’s disease.
BrainStorm is also collaborating with the NVIDIA BioNeMo team to help optimize open-source access to the Geneformer model.
Accelerating Drug Discovery Research
With its proprietary platform, BrainStorm can mirror human brain biology and simulate how different treatments might work in a patient’s brain.
“This can be done thousands of times, much quicker and much cheaper than can be done in a wet lab — so we can narrow down therapeutic options very quickly,” Gosztyla said. “Then we can go in with organoids and test the subset of drugs the AI model thinks will be effective. Only after it gets through those steps will we actually test these drugs in humans.”
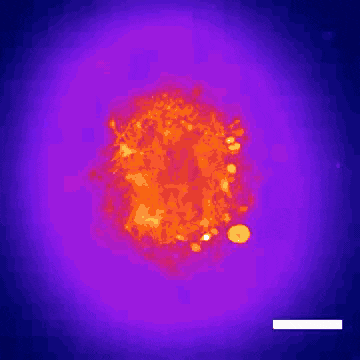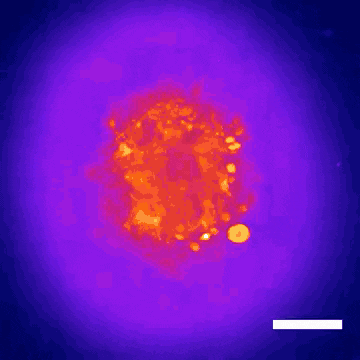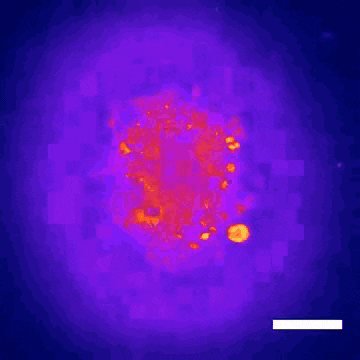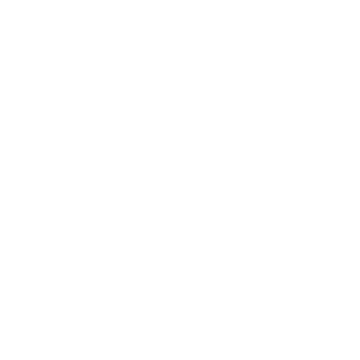
This technology led to the discovery that Donepezil, a drug prescribed for Alzheimer’s disease, could also be effective in treating Rett syndrome, a rare genetic neurodevelopmental disorder. Within nine months, the BrainStorm team was able to go from organoid screening to applying for a phase 2 clinical trial of the drug in Rett patients. This application was recently cleared by the U.S. Food and Drug Administration.
BrainStorm also plans to develop multimodal AI models that integrate data from cell sequencing, cell imaging, EEG scans and more.
“You need high-quality, multimodal input data to design the right drugs,” said Yin. “AI models trained on this data will help us understand disease better, find more effective drug candidates and, eventually, find prognostic biomarkers for specific patients that enable the delivery of precision medicine.”
The company’s next project is an initiative with the CURE5 Foundation to conduct the most comprehensive repurposed drug screen to date for CDKL5 Deficiency Disorder, another rare genetic neurodevelopmental disorder.
“Rare disease research is transforming from a high-risk niche to a dynamic frontier,” said Fremeau. “The integration of BrainStorm’s AI-powered organoid technology with NVIDIA accelerated computing resources and the NVIDIA BioNeMo platform is dramatically accelerating the pace of innovation while reducing the cost — so what once required a decade and billions of dollars can now be investigated with significantly leaner resources in a matter of months.”
Get started with NVIDIA BioNeMo for AI-accelerated drug discovery.
About 15% of the world’s population — over a billion people — are affected by neurological disorders, from commonly known diseases like Alzheimer’s and Parkinson’s to hundreds of lesser-known, rare conditions. BrainStorm Therapeutics, a San Diego-based startup, is accelerating the development of cures for these conditions using AI-powered computational drug discovery paired with lab experiments
Read Article
Project G-Assist Plug-In Builder Lets Anyone Customize AI on GeForce RTX AI PCson April 23, 2025 at 1:00 pm
AI is rapidly reshaping what’s possible on a PC — whether for real-time image generation or voice-controlled workflows. As AI capabilities grow, so does their complexity. Tapping into the power of AI can entail navigating a maze of system settings, software and hardware configurations. Enabling users to explore how on-device AI can simplify and enhance
Read ArticleAI is rapidly reshaping what’s possible on a PC — whether for real-time image generation or voice-controlled workflows. As AI capabilities grow, so does their complexity. Tapping into the power of AI can entail navigating a maze of system settings, software and hardware configurations. Enabling users to explore how on-device AI can simplify and enhance
Read Article
AI is rapidly reshaping what’s possible on a PC — whether for real-time image generation or voice-controlled workflows. As AI capabilities grow, so does their complexity. Tapping into the power of AI can entail navigating a maze of system settings, software and hardware configurations.
Enabling users to explore how on-device AI can simplify and enhance the PC experience, Project G-Assist — an AI assistant that helps tune, control and optimize GeForce RTX systems — is now available as an experimental feature in the NVIDIA app. Developers can try out AI-powered voice and text commands for tasks like monitoring performance, adjusting settings and interacting with supporting peripherals. Users can even summon other AIs powered by GeForce RTX AI PCs.
And it doesn’t stop there. For those looking to expand Project G-Assist capabilities in creative ways, the AI supports custom plug-ins. With the new ChatGPT-based G-Assist Plug-In Builder, developers and enthusiasts can create and customize G-Assist’s functionality, adding new commands, connecting external tools and building AI workflows tailored to specific needs. With the plug-in builder, users can generate properly formatted code with AI, then integrate the code into G-Assist — enabling quick, AI-assisted functionality that responds to text and voice commands.
Teaching PCs New Tricks: Plug-Ins and APIs Explained
Plug-ins are lightweight add-ons that give software new capabilities. G-Assist plug-ins can control music, connect with large language models and much more.
Under the hood, these plug-ins tap into application programming interfaces (APIs), which allow different software and services to talk to each other. Developers can define functions in simple JSON formats, write logic in Python and quickly integrate new tools or features into G-Assist.
With the G-Assist Plug-In Builder, users can:
- Use a responsive small language model running locally on GeForce RTX GPUs for fast, private inference.
- Extend G-Assist’s capabilities with custom functionality tailored to specific workflows, games and tools.
- Interact with G-Assist directly from the NVIDIA overlay, without tabbing out of an application or workflow.
- Invoke AI-powered GPU and system controls from applications using C++ and Python bindings.
- Integrate with agentic frameworks using tools like Langflow, letting G-Assist function as a component in larger AI pipelines and multi-agent systems.
Built for Builders: Using Free APIs to Expand AI PC Capabilities
NVIDIA’s GitHub repository provides everything needed to get started on developing with G-Assist — including sample plug-ins, step-by-step instructions and documentation for building custom functionalities.
Developers can define functions in JSON and drop config files into a designated directory, where G-Assist can automatically load and interpret them. Users can even submit plug-ins for review and potential inclusion in the NVIDIA GitHub repository to make new capabilities available for others.
Hundreds of free, developer-friendly APIs are available today to extend G-Assist capabilities — from automating workflows to optimizing PC setups to boosting online shopping. For ideas, find searchable indices of free APIs for use across entertainment, productivity, smart home, hardware and more on publicapis.dev, free-apis.github.io, apilist.fun and APILayer.
Available sample plug-ins include Spotify, which enables hands-free music and volume control, and Google Gemini, which allows G-Assist to invoke a much larger cloud-based AI for more complex conversations, brainstorming and web searches using a free Google AI Studio API key.
In the clip below, G-Assist asks Gemini for advice on which Legend to pick in the hit game Apex Legends when solo queueing, as well as whether it’s wise to jump into Nightmare mode for level 25 in Diablo IV:
And in the following clip, a developer uses the new plug-in builder to create a Twitch plug-in for G-Assist that checks if a streamer is live. After generating the necessary JSON manifest and Python files, the developer simply drops them into the G-Assist directory to enable voice commands like, “Hey, Twitch, is [streamer] live?”
In addition, users can customize G-Assist to control select peripherals and software applications with simple commands, such as to benchmark or adjust fan speeds, or to change lighting on supported Logitech G, Corsair, MSI and Nanoleaf devices.
Other examples include a Stock Checker plug-in that lets users quickly look up real-time stock prices and performance data, or a Weather plug-in allows users to ask G-Assist for current weather conditions in any city.
Details on how to build, share and load plug-ins are available on the NVIDIA GitHub repository.
Start Building Today
With the G-Assist Plugin Builder and open API support, anyone can extend G-Assist to fit their exact needs. Explore the GitHub repository and submit features for review to help shape the next wave of AI-powered PC experiences.
Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter.
Follow NVIDIA Workstation on LinkedIn and X.
See notice regarding software product information.
AI is rapidly reshaping what’s possible on a PC — whether for real-time image generation or voice-controlled workflows. As AI capabilities grow, so does their complexity. Tapping into the power of AI can entail navigating a maze of system settings, software and hardware configurations. Enabling users to explore how on-device AI can simplify and enhance
Read Article
Enterprises Onboard AI Teammates Faster With NVIDIA NeMo Tools to Scale Employee Productivityon April 23, 2025 at 1:02 pm
An AI agent is only as accurate, relevant and timely as the data that powers it. Now generally available, NVIDIA NeMo microservices are helping enterprise IT quickly build AI teammates that tap into data flywheels to scale employee productivity. The microservices provide an end-to-end developer platform for creating state-of-the-art agentic AI systems and continually optimizing
Read ArticleAn AI agent is only as accurate, relevant and timely as the data that powers it. Now generally available, NVIDIA NeMo microservices are helping enterprise IT quickly build AI teammates that tap into data flywheels to scale employee productivity. The microservices provide an end-to-end developer platform for creating state-of-the-art agentic AI systems and continually optimizing
Read Article
An AI agent is only as accurate, relevant and timely as the data that powers it.
Now generally available, NVIDIA NeMo microservices are helping enterprise IT quickly build AI teammates that tap into data flywheels to scale employee productivity. The microservices provide an end-to-end developer platform for creating state-of-the-art agentic AI systems and continually optimizing them with data flywheels informed by inference and business data, as well as user preferences.
With a data flywheel, enterprise IT can onboard AI agents as digital teammates. These agents can tap into user interactions and data generated during AI inference to continuously improve model performance — turning usage into insight and insight into action.
Building Powerful Data Flywheels for Agentic AI
Without a constant stream of high-quality inputs — from databases, user interactions or real-world signals — an agent’s understanding can weaken, making responses less reliable and agents less productive.
Maintaining and improving the models that power AI agents in production requires three types of data: inference data to gather insights and adapt to evolving data patterns, up-to-date business data to provide intelligence, and user feedback data to advise if the model and application are performing as expected. NeMo microservices help developers tap into these three data types.
NeMo microservices speed AI agent development with end-to-end tools for curating, customizing, evaluating and guardrailing the models that drive their agents.
NVIDIA NeMo microservices — including NeMo Customizer, NeMo Evaluator and NeMo Guardrails — can be used alongside NeMo Retriever and NeMo Curator to ease enterprises’ experiences building, optimizing and scaling AI agents through custom enterprise data flywheels. For example:
- NeMo Customizer accelerates large language model fine-tuning, delivering up to 1.8x higher training throughput. This high-performance, scalable microservice uses popular post-training techniques including supervised fine-tuning and low-rank adaptation.
- NeMo Evaluator simplifies the evaluation of AI models and workflows on custom and industry benchmarks with just five application programming interface (API) calls.
- NeMo Guardrails improves compliance protection by up to 1.4x with only half a second of additional latency, helping organizations implement robust safety and security measures that align with organizational policies and guidelines.
With NeMo microservices, developers can build data flywheels that boost AI agent accuracy and efficiency. Deployed through the NVIDIA AI Enterprise software platform, NeMo microservices are easy to operate and can run on any accelerated computing infrastructure, on premises or in the cloud, with enterprise-grade security, stability and support.
The microservices have become generally available at a time when enterprises are building large-scale multi-agent systems, where hundreds of specialized agents — with distinct goals and workflows — collaborate to tackle complex tasks as digital teammates, working alongside employees to assist, augment and accelerate work across functions.
This enterprise-wide impact positions AI agents as a trillion-dollar opportunity — with applications spanning automated fraud detection, shopping assistants, predictive machine maintenance and document review — and underscores the critical role data flywheels play in transforming business data into actionable insights.
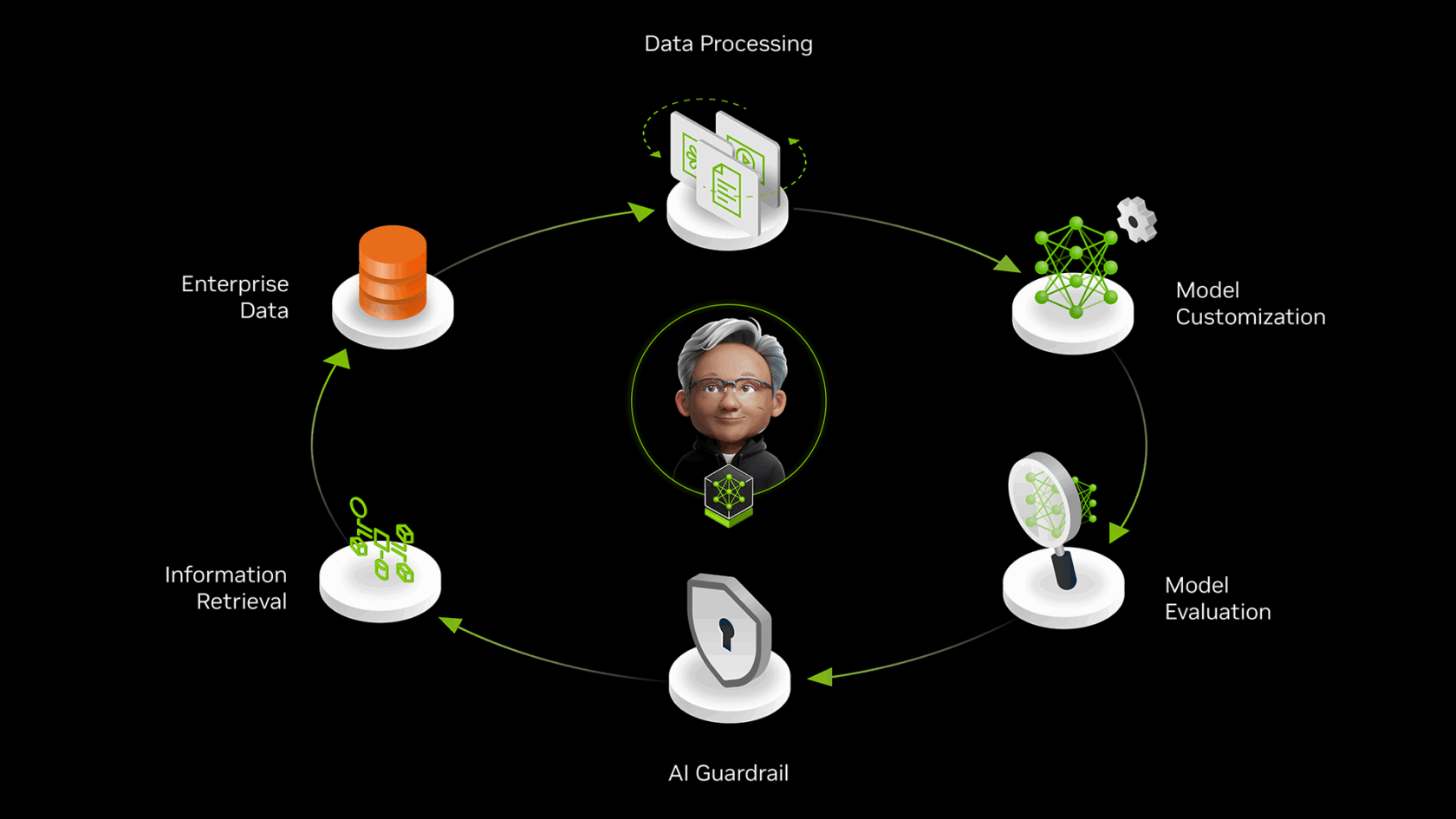
Industry Pioneers Boost AI Agent Accuracy With NeMo Microservices
NVIDIA partners and industry pioneers are using NeMo microservices to build responsive AI agent platforms so that digital teammates can help get more done.
Working with Arize and Quantiphi, AT&T has built an advanced AI-powered agent using NVIDIA NeMo, designed to process a knowledge base of nearly 10,000 documents, refreshed weekly. The scalable, high-performance AI agent is fine-tuned for three key business priorities: speed, cost efficiency and accuracy — all increasingly critical as adoption scales.
AT&T boosted AI agent accuracy by up to 40% using NeMo Customizer and Evaluator by fine-tuning a Mistral 7B model to help deliver personalized services, prevent fraud and optimize network performance.
BlackRock is working with NeMo microservices for agentic AI capabilities in its Aladdin tech platform, which unifies the investment management process through a common data language.
Teaming with Galileo, Cisco’s Outshift team is using NVIDIA NeMo microservices to power a coding assistant that delivers 40% fewer tool selection errors and achieves up to 10x faster response times.
Nasdaq is accelerating its Nasdaq Gen AI Platform with NeMo Retriever microservices and NVIDIA NIM microservices. NeMo Retriever enhanced the platform’s search capabilities, leading to up to 30% improved accuracy and response times, in addition to cost savings.
Broad Model and Partner Ecosystem Support for NeMo Microservices
NeMo microservices support a broad range of popular open models, including Llama, the Microsoft Phi family of small language models, Google Gemma, Mistral and Llama Nemotron Ultra, currently the top open model on scientific reasoning, coding and complex math benchmarks.
Meta has tapped NVIDIA NeMo microservices through new connectors for Meta Llamastack. Users can access the same capabilities — including Customizer, Evaluator and Guardrails — via APIs, enabling them to run the full suite of agent-building workflows within their environment.
“With Llamastack integration, agent builders can implement data flywheels powered by NeMo microservices,” said Raghotham Murthy, software engineer, GenAI, at Meta. “This allows them to continuously optimize models to improve accuracy, boost efficiency and reduce total cost of ownership.”
Leading AI software providers such as Cloudera, Datadog, Dataiku, DataRobot, DataStax, SuperAnnotate, Weights & Biases and more have integrated NeMo microservices into their platforms. Developers can use NeMo microservices in popular AI frameworks including CrewAI, Haystack by deepset, LangChain, LlamaIndex and Llamastack.
Enterprises can build data flywheels with NeMo Retriever microservices using NVIDIA AI Data Platform offerings from NVIDIA-Certified Storage partners including DDN, Dell Technologies, Hewlett Packard Enterprise, Hitachi Vantara, IBM, NetApp, Nutanix, Pure Storage, VAST Data and WEKA.
Leading enterprise platforms including Amdocs, Cadence, Cohesity, SAP, ServiceNow and Synopsys are using NeMo Retriever microservices in their AI agent solutions.
Enterprises can run AI agents on NVIDIA-accelerated infrastructure, networking and software from leading system providers including Cisco, Dell, Hewlett Packard Enterprise and Lenovo.
Consulting giants including Accenture, Deloitte and EY are building AI agent platforms for enterprises using NeMo microservices.
Developers can download NeMo microservices from the NVIDIA NGC catalog. The microservices can be deployed as part of NVIDIA AI Enterprise with extended-life software branches for API stability, proactive security remediation and enterprise-grade support.
An AI agent is only as accurate, relevant and timely as the data that powers it. Now generally available, NVIDIA NeMo microservices are helping enterprise IT quickly build AI teammates that tap into data flywheels to scale employee productivity. The microservices provide an end-to-end developer platform for creating state-of-the-art agentic AI systems and continually optimizing
Read Article
How the Economics of Inference Can Maximize AI Valueon April 23, 2025 at 3:00 pm
As AI models evolve and adoption grows, enterprises must perform a delicate balancing act to achieve maximum value. That’s because inference — the process of running data through a model to get an output — offers a different computational challenge than training a model. Pretraining a model — the process of ingesting data, breaking it
Read ArticleAs AI models evolve and adoption grows, enterprises must perform a delicate balancing act to achieve maximum value. That’s because inference — the process of running data through a model to get an output — offers a different computational challenge than training a model. Pretraining a model — the process of ingesting data, breaking it
Read Article
As AI models evolve and adoption grows, enterprises must perform a delicate balancing act to achieve maximum value.
That’s because inference — the process of running data through a model to get an output — offers a different computational challenge than training a model.
Pretraining a model — the process of ingesting data, breaking it down into tokens and finding patterns — is essentially a one-time cost. But in inference, every prompt to a model generates tokens, each of which incur a cost.
That means that as AI model performance and use increases, so do the amount of tokens generated and their associated computational costs. For companies looking to build AI capabilities, the key is generating as many tokens as possible — with maximum speed, accuracy and quality of service — without sending computational costs skyrocketing.
As such, the AI ecosystem has been working to make inference cheaper and more efficient. Inference costs have been trending down for the past year thanks to major leaps in model optimization, leading to increasingly advanced, energy-efficient accelerated computing infrastructure and full-stack solutions.
According to the Stanford University Institute for Human-Centered AI’s 2025 AI Index Report, “the inference cost for a system performing at the level of GPT-3.5 dropped over 280-fold between November 2022 and October 2024. At the hardware level, costs have declined by 30% annually, while energy efficiency has improved by 40% each year. Open-weight models are also closing the gap with closed models, reducing the performance difference from 8% to just 1.7% on some benchmarks in a single year. Together, these trends are rapidly lowering the barriers to advanced AI.”
As models evolve and generate more demand and create more tokens, enterprises need to scale their accelerated computing resources to deliver the next generation of AI reasoning tools or risk rising costs and energy consumption.
What follows is a primer to understand the concepts of the economics of inference, enterprises can position themselves to achieve efficient, cost-effective and profitable AI solutions at scale.
Key Terminology for the Economics of AI Inference
Knowing key terms of the economics of inference helps set the foundation for understanding its importance.
Tokens are the fundamental unit of data in an AI model. They’re derived from data during training as text, images, audio clips and videos. Through a process called tokenization, each piece of data is broken down into smaller constituent units. During training, the model learns the relationships between tokens so it can perform inference and generate an accurate, relevant output.
Throughput refers to the amount of data — typically measured in tokens — that the model can output in a specific amount of time, which itself is a function of the infrastructure running the model. Throughput is often measured in tokens per second, with higher throughput meaning greater return on infrastructure.
Latency is a measure of the amount of time between inputting a prompt and the start of the model’s response. Lower latency means faster responses. The two main ways of measuring latency are:
- Time to First Token: A measurement of the initial processing time required by the model to generate its first output token after a user prompt.
- Time per Output Token: The average time between consecutive tokens — or the time it takes to generate a completion token for each user querying the model at the same time. It’s also known as “inter-token latency” or token-to-token latency.
Time to first token and time per output token are helpful benchmarks, but they’re just two pieces of a larger equation. Focusing solely on them can still lead to a deterioration of performance or cost.
To account for other interdependencies, IT leaders are starting to measure “goodput,” which is defined as the throughput achieved by a system while maintaining target time to first token and time per output token levels. This metric allows organizations to evaluate performance in a more holistic manner, ensuring that throughput, latency and cost are aligned to support both operational efficiency and an exceptional user experience.
Energy efficiency is the measure of how effectively an AI system converts power into computational output, expressed as performance per watt. By using accelerated computing platforms, organizations can maximize tokens per watt while minimizing energy consumption.
How the Scaling Laws Apply to Inference Cost
The three AI scaling laws are also core to understanding the economics of inference:
- Pretraining scaling: The original scaling law that demonstrated that by increasing training dataset size, model parameter count and computational resources, models can achieve predictable improvements in intelligence and accuracy.
- Post-training: A process where models are fine-tuned for accuracy and specificity so they can be applied to application development. Techniques like retrieval-augmented generation can be used to return more relevant answers from an enterprise database.
- Test-time scaling (aka “long thinking” or “reasoning”): A technique by which models allocate additional computational resources during inference to evaluate multiple possible outcomes before arriving at the best answer.
While AI is evolving and post-training and test-time scaling techniques become more sophisticated, pretraining isn’t disappearing and remains an important way to scale models. Pretraining will still be needed to support post-training and test-time scaling.
Profitable AI Takes a Full-Stack Approach
In comparison to inference from a model that’s only gone through pretraining and post-training, models that harness test-time scaling generate multiple tokens to solve a complex problem. This results in more accurate and relevant model outputs — but is also much more computationally expensive.
Smarter AI means generating more tokens to solve a problem. And a quality user experience means generating those tokens as fast as possible. The smarter and faster an AI model is, the more utility it will have to companies and customers.
Enterprises need to scale their accelerated computing resources to deliver the next generation of AI reasoning tools that can support complex problem-solving, coding and multistep planning without skyrocketing costs.
This requires both advanced hardware and a fully optimized software stack. NVIDIA’s AI factory product roadmap is designed to deliver the computational demand and help solve for the complexity of inference, while achieving greater efficiency.
AI factories integrate high-performance AI infrastructure, high-speed networking and optimized software to produce intelligence at scale. These components are designed to be flexible and programmable, allowing businesses to prioritize the areas most critical to their models or inference needs.
To further streamline operations when deploying massive AI reasoning models, AI factories run on a high-performance, low-latency inference management system that ensures the speed and throughput required for AI reasoning are met at the lowest possible cost to maximize token revenue generation.
Learn more by reading the ebook “AI Inference: Balancing Cost, Latency and Performance.”
As AI models evolve and adoption grows, enterprises must perform a delicate balancing act to achieve maximum value. That’s because inference — the process of running data through a model to get an output — offers a different computational challenge than training a model. Pretraining a model — the process of ingesting data, breaking it
Read Article
Capital One Banks on AI for Financial Serviceson April 23, 2025 at 4:00 pm
Financial services has long been at the forefront of adopting technological innovations. Today, generative AI and agentic systems are redefining the industry, from customer interactions to enterprise operations. Prem Natarajan, executive vice president, chief scientist and head of AI at Capital One, joined the NVIDIA AI Podcast to discuss how his organization is building proprietary
Read ArticleFinancial services has long been at the forefront of adopting technological innovations. Today, generative AI and agentic systems are redefining the industry, from customer interactions to enterprise operations. Prem Natarajan, executive vice president, chief scientist and head of AI at Capital One, joined the NVIDIA AI Podcast to discuss how his organization is building proprietary
Read Article
Financial services has long been at the forefront of adopting technological innovations. Today, generative AI and agentic systems are redefining the industry, from customer interactions to enterprise operations.
Prem Natarajan, executive vice president, chief scientist and head of AI at Capital One, joined the NVIDIA AI Podcast to discuss how his organization is building proprietary AI systems that deliver value to over 100 million customers.
“AI is at its best when it transfers cognitive burden from the human to the system,” Natarajan said. “It allows the human to have that much more fun and experience that magic.”
Capital One’s strategy centers on a “test, iterate, refine” approach that balances innovation with rigorous risk management. The company’s first agentic AI deployment is a chat concierge that helps customers navigate the car-buying process, such as by scheduling test drives.
Rather than simply integrating third-party solutions, Capital One builds proprietary AI technologies that tap into its vast data repositories.
“Your data advantage is your AI advantage,” Natarajan emphasized. “Proprietary data allows you to build proprietary AI that provides enduring differentiated services for your customers.”
Capital One’s AI architecture combines open-weight foundation models with deep customizations using proprietary data. This approach, Natarajan explained, supports the creation of specialized models that excel at financial services tasks and integrate into multi-agent workflows that can take actions.
Natarajan stressed that responsible AI is fundamental to Capital One’s design process. His teams take a “responsibility through design” approach, implementing robust guardrails — both technological and human-in-the-loop — to ensure safe deployment.
The concept of an AI factory — where raw data is processed and refined to produce actionable intelligence — aligns naturally with Capital One’s cloud-native technology stack. AI factories incorporate all the components required for financial institutions to generate intelligence, combining hardware, software, networking and development tools for AI applications in financial services.
Time Stamps
1:10 – Natarajan’s background and journey to Capital One.
4:50 – Capital One’s approach to generative AI and agentic systems.
15:56 – Challenges in implementing responsible AI in financial services.
28:46 – AI factories and Capital One’s cloud-native advantage.
You Might Also Like…
NVIDIA’s Jacob Liberman on Bringing Agentic AI to Enterprises
Agentic AI enables developers to create intelligent multi-agent systems that reason, act and execute complex tasks with a degree of autonomy. Jacob Liberman, director of product management at NVIDIA, explains how agentic AI bridges the gap between powerful AI models and practical enterprise applications.
Telenor Builds Norway’s First AI Factory, Offering Sustainable and Sovereign Data Processing
Telenor opened Norway’s first AI factory in November 2024, enabling organizations to process sensitive data securely on Norwegian soil while prioritizing environmental responsibility. Telenor’s Chief Innovation Officer and Head of the AI Factory Kaaren Hilsen discusses the AI factory’s rapid development, going from concept to reality in under a year.
Imbue CEO Kanjun Qiu on Transforming AI Agents Into Personal Collaborators
Kanjun Qiu, CEO of Imbue, explores the emerging era where individuals can create and use their own AI agents. Drawing a parallel to the PC revolution of the late 1970s and ‘80s, Qiu discusses how modern AI systems are evolving to work collaboratively with users, enhancing their capabilities rather than just automating tasks.
Financial services has long been at the forefront of adopting technological innovations. Today, generative AI and agentic systems are redefining the industry, from customer interactions to enterprise operations. Prem Natarajan, executive vice president, chief scientist and head of AI at Capital One, joined the NVIDIA AI Podcast to discuss how his organization is building proprietary
Read Article
NVIDIA Research at ICLR — Pioneering the Next Wave of Multimodal Generative AIon April 24, 2025 at 1:00 pm
Advancing AI requires a full-stack approach, with a powerful foundation of computing infrastructure — including accelerated processors and networking technologies — connected to optimized compilers, algorithms and applications. NVIDIA Research is innovating across this spectrum, supporting virtually every industry in the process. At this week’s International Conference on Learning Representations (ICLR), taking place April 24-28
Read ArticleAdvancing AI requires a full-stack approach, with a powerful foundation of computing infrastructure — including accelerated processors and networking technologies — connected to optimized compilers, algorithms and applications. NVIDIA Research is innovating across this spectrum, supporting virtually every industry in the process. At this week’s International Conference on Learning Representations (ICLR), taking place April 24-28
Read Article
Advancing AI requires a full-stack approach, with a powerful foundation of computing infrastructure — including accelerated processors and networking technologies — connected to optimized compilers, algorithms and applications.
NVIDIA Research is innovating across this spectrum, supporting virtually every industry in the process. At this week’s International Conference on Learning Representations (ICLR), taking place April 24-28 in Singapore, more than 70 NVIDIA-authored papers introduce AI developments with applications in autonomous vehicles, healthcare, multimodal content creation, robotics and more.
“ICLR is one of the world’s most impactful AI conferences, where researchers introduce important technical innovations that move every industry forward,” said Bryan Catanzaro, vice president of applied deep learning research at NVIDIA. “The research we’re contributing this year aims to accelerate every level of the computing stack to amplify the impact and utility of AI across industries.”
Research That Tackles Real-World Challenges
Several NVIDIA-authored papers at ICLR cover groundbreaking work in multimodal generative AI and novel methods for AI training and synthetic data generation, including:
- Fugatto: The world’s most flexible audio generative AI model, Fugatto generates or transforms any mix of music, voices and sounds described with prompts using any combination of text and audio files. Other NVIDIA models at ICLR improve audio large language models (LLMs) to better understand speech.
- HAMSTER: This paper demonstrates that a hierarchical design for vision-language-action models can improve their ability to transfer knowledge from off-domain fine-tuning data — inexpensive data that doesn’t need to be collected on actual robot hardware — to improve a robot’s skills in testing scenarios.
- Hymba: This family of small language models uses a hybrid model architecture to create LLMs that blend the benefits of transformer models and state space models, enabling high-resolution recall, efficient context summarization and common-sense reasoning tasks. With its hybrid approach, Hymba improves throughput by 3x and reduces cache by almost 4x without sacrificing performance.
- LongVILA: This training pipeline enables efficient visual language model training and inference for long video understanding. Training AI models on long videos is compute and memory-intensive — so this paper introduces a system that efficiently parallelizes long video training and inference, with training scalability up to 2 million tokens on 256 GPUs. LongVILA achieves state-of-the-art performance across nine popular video benchmarks.
- LLaMaFlex: This paper introduces a new zero-shot generation technique to create a family of compressed LLMs based on one large model. The researchers found that LLaMaFlex can generate compressed models that are as accurate or better than state-of-the art pruned, flexible and trained-from-scratch models — a capability that could be applied to significantly reduce the cost of training model families compared to techniques like pruning and knowledge distillation.
- Proteina: This model can generate diverse and designable protein backbones, the framework that holds a protein together. It uses a transformer model architecture with up to 5x as many parameters as previous models.
- SRSA: This framework addresses the challenge of teaching robots new tasks using a preexisting skill library — so instead of learning from scratch, a robot can apply and adapt its existing skills to the new task. By developing a framework to predict which preexisting skill would be most relevant to a new task, the researchers were able to improve zero-shot success rates on unseen tasks by 19%.
- STORM: This model can reconstruct dynamic outdoor scenes — like cars driving or trees swaying in the wind — with a precise 3D representation inferred from just a few snapshots. The model, which can reconstruct large-scale outdoor scenes in 200 milliseconds, has potential applications in autonomous vehicle development.
Discover the latest work from NVIDIA Research, a global team of around 400 experts in fields including computer architecture, generative AI, graphics, self-driving cars and robotics.
Advancing AI requires a full-stack approach, with a powerful foundation of computing infrastructure — including accelerated processors and networking technologies — connected to optimized compilers, algorithms and applications. NVIDIA Research is innovating across this spectrum, supporting virtually every industry in the process. At this week’s International Conference on Learning Representations (ICLR), taking place April 24-28
Read Article
All Roads Lead Back to Oblivion: Bethesda’s ‘The Elder Scrolls IV: Oblivion Remastered’ Arrives on GeForce NOWon April 24, 2025 at 1:00 pm
Get the controllers ready and clear the calendar — it’s a jam-packed GFN Thursday. Time to revisit a timeless classic for a dose of remastered nostalgia. GeForce NOW is bringing members a surprise from Bethesda — The Elder Scrolls IV: Oblivion Remastered is now available in the cloud. Clair Obscur: Expedition 33, the spellbinding turn-based
Read ArticleGet the controllers ready and clear the calendar — it’s a jam-packed GFN Thursday. Time to revisit a timeless classic for a dose of remastered nostalgia. GeForce NOW is bringing members a surprise from Bethesda — The Elder Scrolls IV: Oblivion Remastered is now available in the cloud. Clair Obscur: Expedition 33, the spellbinding turn-based
Read Article
Get the controllers ready and clear the calendar — it’s a jam-packed GFN Thursday.
Time to revisit a timeless classic for a dose of remastered nostalgia. GeForce NOW is bringing members a surprise from Bethesda — The Elder Scrolls IV: Oblivion Remastered is now available in the cloud.
Clair Obscur: Expedition 33, the spellbinding turn-based role-playing game, is ready to paint its adventure across GeForce NOW for members to stream in style.
Sunderfolk, from Dreamhaven’s Secret Door studio, launches on GeForce NOW, following an exclusive First Look Demo for members.
And get ready to crack the case with the sharpest minds in the business — Capcom’s Ace Attorney Investigations Collection heads to the cloud this week, offering members the thrilling adventures of prosecutor Miles Edgeworth.
Stream it all across devices, along with eight other games added to the cloud this week, including Zenless Zone Zero’s latest update.
A Legendary Quest

Step back into the world of Cyrodiil in style with the award-winning The Elder Scrolls IV: Oblivion Remastered in the cloud. The revitalization of the iconic 2006 role-playing game offers updated visuals, gameplay and plenty of more content.
Explore a meticulously recreated world, navigate story paths as diverse character archetypes and engage in an epic quest to save Tamriel from a Daedric invasion. The remaster includes all previously released expansions — Shivering Isles, Knights of the Nine and additional downloadable content — providing a comprehensive experience for new and returning fans.
Rediscover the vast landscape of Cyrodiil like never before with a GeForce NOW membership and stop the forces of Oblivion from overtaking the land. Ultimate and Performance members enjoy higher resolutions and longer gaming sessions for immersive gaming anytime, anywhere.
A Whole New World
Sunderfolk is a turn-based tactical role-playing adventure for up to four players that offers an engaging couch co-op experience. Control characters using a smartphone app, which serves as both a controller and a hub for cards, inventory and rules.

In the underground fantasy world of Arden, take on the roles of anthropomorphic animal heroes tasked with defending their town from the corruption of shadowstone. Six unique classes — from the fiery Pyromancer salamander to the tactical Bard bat — are equipped with distinct skill cards. Missions range from combat and exploration to puzzles and rescues, requiring teamwork and coordination.
Get into the mischief streaming it on GeForce NOW. Gather the squad and rekindle the spirit of game night from the comfort of the couch, streaming on the big screen with GeForce NOW and using a mobile device as a controller for a unique, immersive co-op experience.
No Objections Here

Experience both Ace Attorney Investigations games in one gorgeous collection, stepping into the shoes of Miles Edgeworth, the prosecutor of prosecutors from the Ace Attorney mainline games.
Leave the courtroom behind and walk with Edgeworth around the crime scene to gather evidence and clues, including by talking with persons of interest. Solve tough, intriguing cases through wit, logic and deduction.
Members can level up their detective work across devices with a premium GeForce NOW membership. Ultimate and Performance members get extended session times to crack cases without interruptions.
Tears, Fears and Parasol Spears

Zenless Zone Zero v1.7, “Bury Your Tears With the Past,” marks the dramatic conclusion of the first season’s storyline. Team with a special investigator to infiltrate enemy ranks, uncover the truth behind the Exaltists’ conspiracy and explore the mysteries of the Sacrifice Core, adding new depth to the game’s lore and characters.
The update also introduces two new S-Rank Agents — Vivian, a versatile Ether Anomaly fighter, and Hugo, an Ice Attack specialist — each bringing unique combat abilities to the roster. Alongside limited-time events, quality-of-life improvements and more, the update offers fresh gameplay modes and exclusive rewards.
Quest for Fresh Adventures

Clair Obscur: Expedition 33 is a visually stunning, dark fantasy role-playing game available now for members to stream. A mysterious entity called the Paintress erases everyone of a certain age each year after painting their number on a monolith. Join a desperate band of survivors — most with only a year left to live — on the 33rd expedition to end this cycle of death by confronting the Paintress and her monstrous creations. Dodge, parry and counterattack in battle while exploring a richly imagined world inspired by French Belle Époque art and filled with complex, emotionally driven characters.
Look for the following games available to stream in the cloud this week:
- The Elder Scrolls IV: Oblivion Remastered (New release on Steam and Xbox, available on PC Game Pass, April 22)
- Sunderfolk (New release on Steam, April 23)
- Clair Obscur: Expedition 33 (New release on Steam and Xbox, available on PC Game Pass, April 24)
- Ace Attorney Investigations Collection (Steam and Xbox, available on the Microsoft Store)
- Ace Attorney Investigations Collection Demo (Steam and Xbox, available on the Microsoft Store)
- Dead Rising Deluxe Remaster Demo (Steam)
- EXFIL (Steam)
- Sands of Aura (Epic Games Store)
What are you planning to play this weekend? Let us know on X or in the comments below.
What’s a game on GFN that deserves more love? 💚
— 🌩️ NVIDIA GeForce NOW (@NVIDIAGFN) April 22, 2025
Get the controllers ready and clear the calendar — it’s a jam-packed GFN Thursday. Time to revisit a timeless classic for a dose of remastered nostalgia. GeForce NOW is bringing members a surprise from Bethesda — The Elder Scrolls IV: Oblivion Remastered is now available in the cloud. Clair Obscur: Expedition 33, the spellbinding turn-based
Read Article
CHRISTCHURCH, New Zealand — Taiwanese authorities this month charged the Chinese captain of the cargo vessel Hong Tai 58 for…
The Space Force said Thursday its newest weather satellite is now operational and will soon be collecting and sharing key…